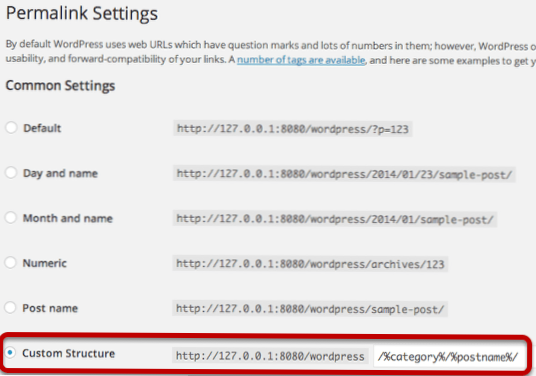
- Wie füge ich eine Sperre in Robots-txt hinzu??
- Was ist in robots txt nicht zulassen??
- Wie ignoriere ich Robots-txt?
- Ist robots txt rechtlich bindend??
- Sollte die Sitemap in Robots-txt sein??
- Welche Art von Seiten sollte durch Robots-txt ausgeschlossen werden??
- Wie überprüfen Sie, ob robots txt funktioniert??
- Wo befindet sich die Robot-txt-Datei??
- Was sollte Roboter-TXT enthalten?
- Was passiert, wenn Sie Robots txt nicht befolgen??
- Ignorieren Suchmaschinen Robots txt??
- Respektiert Google Robots-txt?
Wie füge ich eine Sperre in Robots-txt hinzu??
Beginnen Sie mit der Festlegung des User-Agent-Begriffs. Wir werden es so einstellen, dass es für alle Webroboter gilt. Verwenden Sie dazu ein Sternchen nach dem User-Agent-Begriff, wie folgt: Geben Sie als Nächstes „Disallow:“ ein, aber geben Sie danach nichts mehr ein.
Was ist in robots txt nicht zulassen??
Direktive in Robotern verbieten. TXT. Sie können Suchmaschinen anweisen, nicht auf bestimmte Dateien, Seiten oder Abschnitte Ihrer Website zuzugreifen. Dies geschieht mit der Disallow-Direktive.
Wie ignoriere ich Robots-txt?
Sie können Roboter ignorieren. txt für Ihre Scrapy-Spider, indem Sie die Option ROBOTSTXT_OBEY verwenden und den Wert auf False setzen.
Ist robots txt rechtlich bindend??
Es gibt kein Gesetz, das besagt, dass /Roboter. txt muss befolgt werden und stellt keinen verbindlichen Vertrag zwischen Seiteninhaber und Benutzer dar, sondern hat einen /robots. txt kann in Rechtsfällen relevant sein. Natürlich, IANAL, und wenn Sie Rechtsberatung benötigen, erhalten Sie professionelle Dienstleistungen von einem qualifizierten Anwalt.
Sollte die Sitemap in Robots-txt sein??
XML-Sitemaps können auch zusätzliche Informationen zu jeder URL in Form von Metadaten enthalten. Und genau wie Roboter. txt, eine XML-Sitemap ist ein Muss. Es ist nicht nur wichtig, sicherzustellen, dass Suchmaschinen-Bots alle Ihre Seiten entdecken können, sondern ihnen auch zu helfen, die Bedeutung Ihrer Seiten zu verstehen.
Welche Art von Seiten sollte durch Robots-txt ausgeschlossen werden??
Wenn Ihre Webseite von einem Roboter blockiert wird. txt-Datei, kann es immer noch in den Suchergebnissen erscheinen, aber das Suchergebnis hat keine Beschreibung und sieht in etwa so aus. Bilddateien, Videodateien, PDFs und andere Nicht-HTML-Dateien werden ausgeschlossen.
Wie überprüfen Sie, ob robots txt funktioniert??
Testen Sie Ihre Roboter. txt-Datei
- Öffnen Sie das Tester-Tool für Ihre Site und scrollen Sie durch die Robots. ...
- Geben Sie die URL einer Seite Ihrer Website in das Textfeld unten auf der Seite ein.
- Wählen Sie in der Dropdown-Liste rechts neben dem Textfeld den Benutzeragenten aus, den Sie simulieren möchten.
- Klicken Sie auf die Schaltfläche TEST, um den Zugriff zu testen.
Wo befindet sich die Robot-txt-Datei??
Die Roboter. txt-Datei muss sich im Stammverzeichnis des Website-Hosts befinden, für den sie gilt. Zum Beispiel, um das Crawlen aller URLs unterhalb von http://www . zu steuern.Beispiel.com/ , die Roboter. txt-Datei muss sich unter http://www . befinden.Beispiel.com/roboter.TXT .
Was sollte Roboter-TXT enthalten?
txt-Datei enthält Informationen darüber, wie die Suchmaschine crawlen soll. Die dort gefundenen Informationen weisen die weitere Crawler-Aktion auf dieser bestimmten Site an. Wenn die Roboter. txt-Datei enthält keine Anweisungen, die die Aktivität eines User-Agents verbieten (oder wenn die Site keine Robots hat.
Was passiert, wenn Sie Robots txt nicht befolgen??
3 Antworten. Der Robot Exclusion Standard ist rein beratend, es liegt ganz bei Ihnen, ob Sie ihn befolgen oder nicht, und wenn Sie nichts Böses tun, ist die Wahrscheinlichkeit groß, dass nichts passiert, wenn Sie sich entscheiden, ihn zu ignorieren.
Ignorieren Suchmaschinen Robots txt??
All-Access für alle Bots
Mit anderen Worten, Suchmaschinen ignorieren es. Aus diesem Grund hat diese Richtlinie zum Verbieten keine Auswirkungen auf die Website. Suchmaschinen können weiterhin alle Seiten und Dateien crawlen.
Respektiert Google Robots-txt?
Google hat offiziell angekündigt, dass der GoogleBot keinem Roboter mehr gehorchen wird. txt-Anweisung im Zusammenhang mit der Indexierung. Verlage, die sich auf die Roboter verlassen. txt-noindex-Direktive hat bis zum 1. September 2019 Zeit, sie zu entfernen und eine Alternative zu verwenden.
![Warum die Option „Permalink“ nicht in den „Einstellungen“ angezeigt wird? [geschlossen]](https://usbforwindows.com/storage/img/images_1/why_the_permalink_option_is_not_showing_in_the_settings_closed.png)